
(no title)
scandum | 2 years ago
As you can see, quadsort 1.1.4.1 used 2 instead of 4 writes in the bi-directional parity merges. This was in June 2021, and would have compiled as branchless with clang, but as branched with gcc.
When I added a compile time check to use ternary operations for clang I was not adapting your work. I was well aware that clang compiled ternary operations as branchless, but I wasn't aware that rust did as well. I added the compile time check to use ternary operations for a fair performance comparison against glidesort.
https://raw.githubusercontent.com/scandum/fluxsort/main/imag...
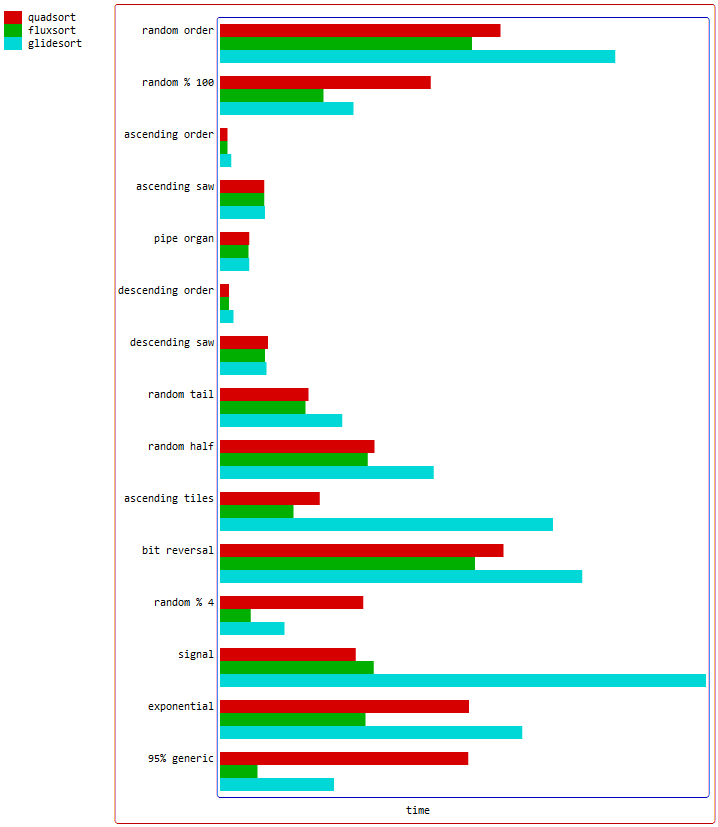{kind=link}
As for ipnsort's small sort, it is very similar to quadsort's small sort, which uses stable sorting networks, instead of unstable sorting networks. From my perspective it's not exactly novel. I didn't go for unstable sorting networks in crumsort to increase code reuse, and to not reduce adaptivity.
No comments yet.