
(no title)
taliesinb | 2 years ago
If anyone is interested in a kind of tensor network-y diagrammatic notation for array programs (of which transformers and other deep neural nets are examples), I wrote a post recently that introduces a kind of "colorful" tensor network notation (where the colors correspond to axis names) and then uses it to describe self-attention and transformers. The actual circuitry to compute one round of self-attention is remarkably compact in this notation:
https://math.tali.link/raster/052n01bav6yvz_1smxhkus2qrik_07...
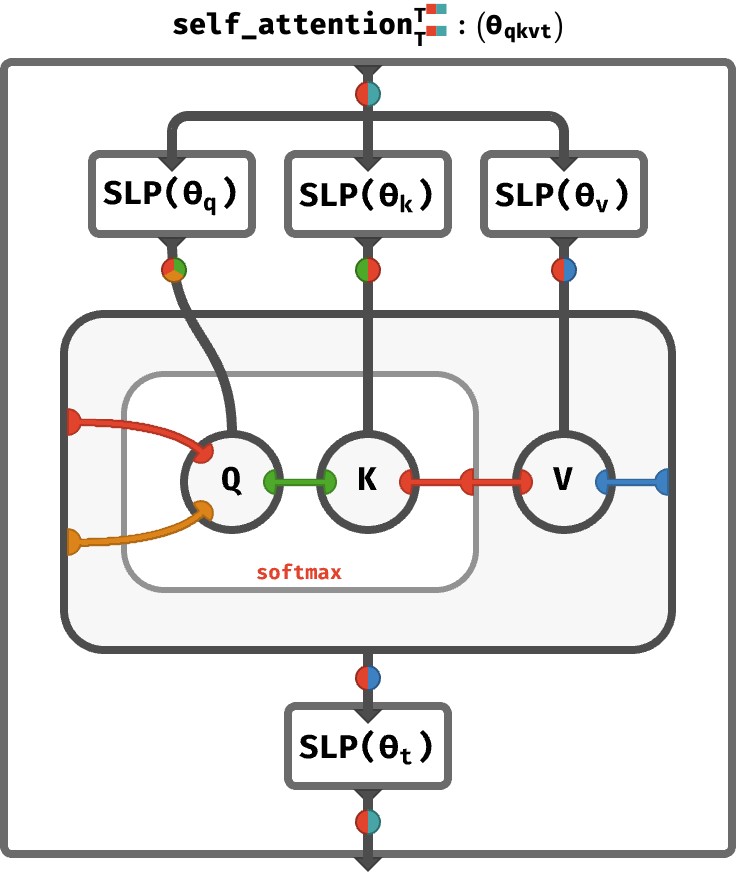{kind=link}
Here's the full section on transformers: https://math.tali.link/rainbow-array-algebra/#transformers -- for more context on this kind of notation and how it conceptualizes "arrays as functions" and "array programs as higher-order functional programming" you can check out https://math.tali.link/classical-array-algebra or skip to the named axis followup at https://math.tali.link/rainbow-array-algebra
3abiton|2 years ago
kridsdale1|2 years ago
And the scale of everything. GPT3 embedding vectors are around 12,000, vs 768 shown here.
I was curious and the 12k figure closely approximates the median synapse dimensionality of human neurons. Maybe we don’t need much more.