
(no title)
unlord | 1 year ago
{kind=link}
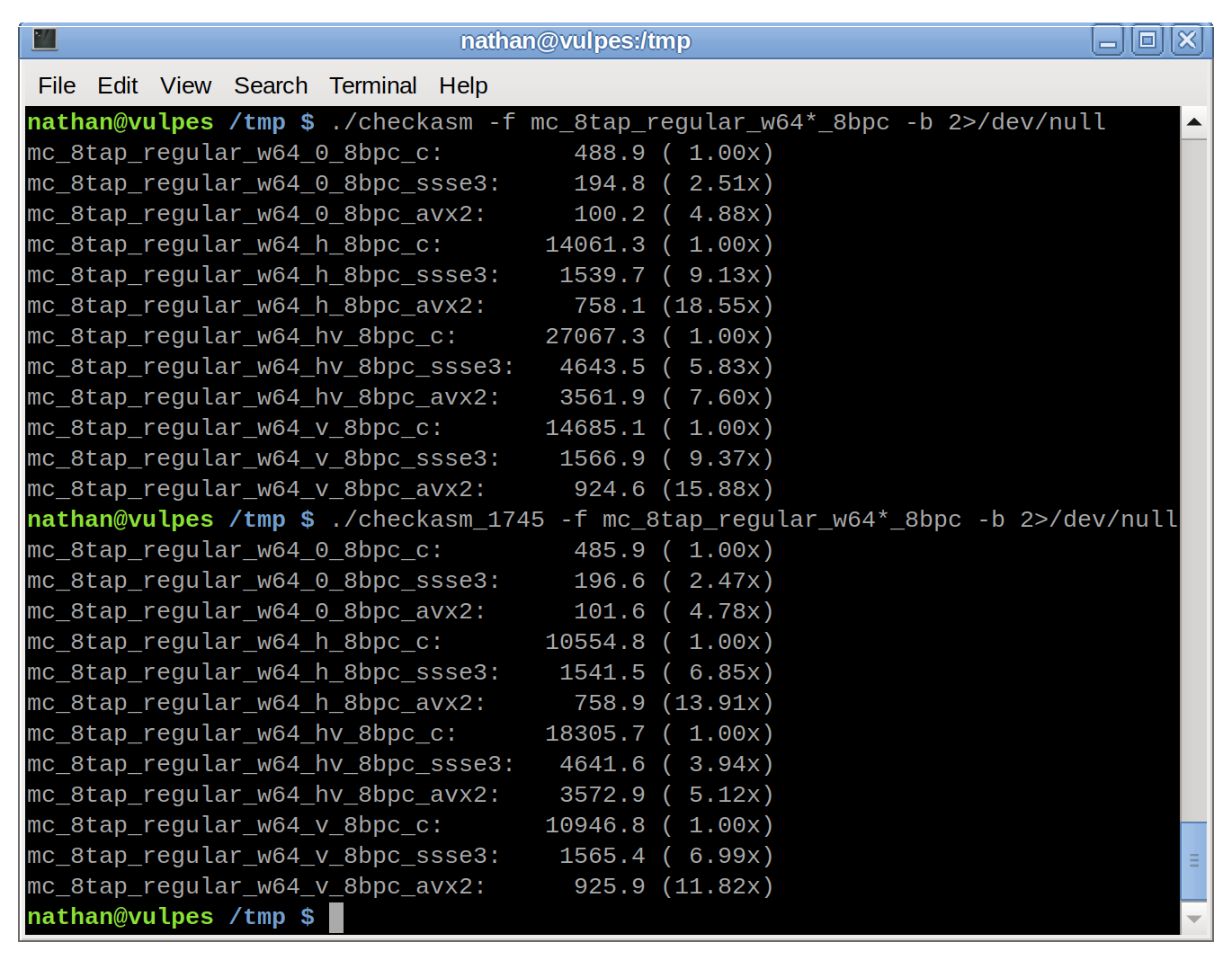
What's more, the C code is running an 8-tap filter where the SIMD for that function (in all of SSSE3, AVX2 and AVX512) is implemented as 6-tap. Last week I posted MR !1745 (https://code.videolan.org/videolan/dav1d/-/merge_requests/17...) which adds 6-tap to the C code and brings improved performance to all platforms dav1d supports.
This, of course, also closes the gap in these numbers but is a more accurate representation of the speed-up from hand-written assembly.
zbobet2012|1 year ago
wscott|1 year ago
The part Intel struggles with is that in many places if they had the 256-bit max width but all the new operations then they could build a machine that is faster than the 512-bit version. (assuming the same code was written for both vector widths) The reason is the ALUs could be faster and you could have more of them.
Dylan16807|1 year ago
But the number of situations where AVX512 has a significant advantage is growing, so interest will grow alongside it.
jsheard|1 year ago
Ironically AMD has stronger AVX512 support at this point despite the spec originating at Intel.