
ayw | 6 years ago | on: AWS Data Exchange
ayw's comments
ayw | 6 years ago | on: Ask HN: Why do so many startups claim machine learning is their long game?
Strongly agree with this.
One thing I’ll mention is that this is true both at the very early stages of a ML project, and even when an ML project is scaled up and in production. Oftentimes, the data pipeline is the true way in which a model will improve versus anything else, so it’s pretty critical that these data pipelines are setup to get an initial dataset but also to scale properly.
It’s one reason I started Scale (scale.com). It was viscerally clear that the real bottleneck to ML was getting the needed data, and in our case, annotating that data appropriately. It is very heartening to hear it echoed in this whole thread that data is very clearly what “matters” for ML.
ayw | 6 years ago | on: Fine-Tuning GPT-2 from Human Preferences
It's a good idea! They didn't demonstrate a lot of the inputs as the models were training, but that was very entertaining of course.
ayw | 6 years ago | on: Fine-Tuning GPT-2 from Human Preferences
founder of Scale (scale.com) here! We worked with OpenAI to produce the human preferences to power this research, and are generally very excited about it :)
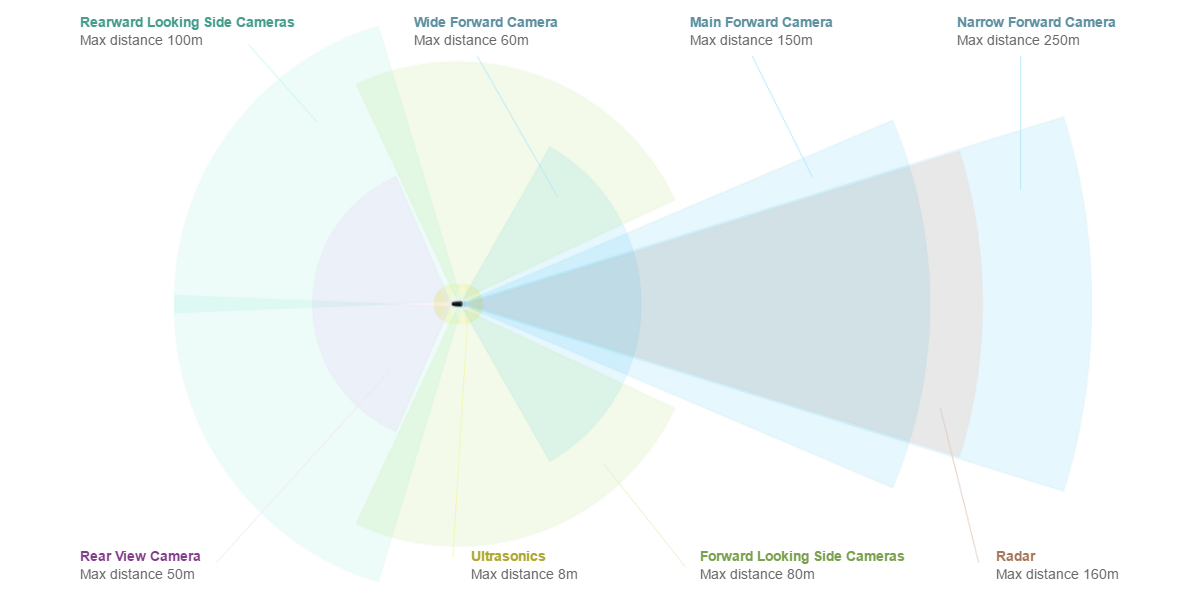
ayw | 6 years ago | on: Is Elon Musk Wrong about Lidar? A Quantitative Study
1. While stereo depth estimation would work in theory, none of the self-driving cars actually have camera configurations that allow for stereo depth estimation (see here: https://electrek.co/wp-content/uploads/sites/3/2016/10/tesla...)
{kind=link}
2. Stereo depth estimation is quite unreliable in practice because it requires you to match up pixels between the two images very precisely (1-2px difference can be a large disparity in distance), so it is not reliably used.
ayw | 6 years ago | on: Scale (YC S16) Raises $100M from Accel and Founders Fund at $1B Valuation
We have many clients who have switched from Hive. There’s usually a step change improvement in quality and scalability—up to 10x improvement in error rates.
ayw | 6 years ago | on: Scale (YC S16) Raises $100M from Accel and Founders Fund at $1B Valuation
We have a rule when hiring people—we look for people with an internal locus of control. Roughly speaking, this means people who believe they have control over outcomes in their life, as opposed to external forces beyond their control.
It’s a small thing, but it’s surprising easy to spot once you look for it. And it really matters—startups are the business of building something from nothing. You need people who believe they can bend the earth.
ayw | 6 years ago | on: Scale (YC S16) Raises $100M from Accel and Founders Fund at $1B Valuation
The biggest change is your jobs goes from doing things (which makes sense) to building an incredible team that can do things (which is a more unintuitive job). In the limit, it’s always a people business.
Overcome many challenges, but per my last answer, building a team of the best people has been the most important and most challenging. That, and learning how to do sales ;)
Too many mentors. People in Silicon Valley are incredibly helpful. To name a few: Dan Levine, Mike Volpi, Nat Friedman, Adam D’Angelo, Ilya Sukhar, Jonathan Swanson, Albert Ni, Jeff Arnold, Charlie Cheever, and Drew Houston to name a few. I’m very very lucky.
ayw | 6 years ago | on: Scale (YC S16) Raises $100M from Accel and Founders Fund at $1B Valuation
Self-driving is one of many applications of AI/ML to the real world, each of which likely requires high-quality labeled data to truly be production-ready. This includes other robotics, self-checkout like Amazon Go, natural language understanding, and more.
Second, self-driving as a problem space will need labels for a very long time. In an application where (1) verifiable model performance is paramount, and (2) the models need to be extremely robust for cars to be safe, the need for labeled data is only magnified.
ayw | 6 years ago | on: Scale (YC S16) Raises $100M from Accel and Founders Fund at $1B Valuation
Thank you! We have some exciting stuff cooking that we can’t wait to share with everyone.
In the meantime, check out our open source datasets:
https://scale.com/open-datasets/nuscenes https://scale.com/open-datasets/pandaset https://level5.lyft.com/dataset/
ayw | 6 years ago | on: Scale (YC S16) Raises $100M from Accel and Founders Fund at $1B Valuation
Re 1—It has been a bit of annoyance growing up (for example, Google autocorrects "Alexandr Wang" to "Alexander Wang"), but we run different circles ;)
Re 2—As with most companies working on ML these days, our stack is not fully proprietary. We don't take too strong an opinion on ML framework and use both Tensorflow and Pytorch currently. We generally use neural network architectures from the literature and then iterate on top of them to suit our unique problem requirements.
ayw | 6 years ago | on: Scale (YC S16) Raises $100M from Accel and Founders Fund at $1B Valuation
To be clear, there is real machine learning that makes the labeling more efficient.
You can see some videos of what this looks like in this Twitter thread: https://twitter.com/BW/status/1158407524216909826
ayw | 6 years ago | on: Scale (YC S16) Raises $100M from Accel and Founders Fund at $1B Valuation
I genuinely am not sure who you're talking about, but good to know!
ayw | 6 years ago | on: Scale (YC S16) Raises $100M from Accel and Founders Fund at $1B Valuation
We do use AI and ML to help making the labeling process more efficient, but you are correct we do have scaled human insight that ensures very high quality.
One difference from "Not Hotdog" is that our data is used to power the algorithms of other AI/ML companies like OpenAI, Waymo, Lyft, etc., so it's imperative that we have impeccable quality. That necessitates humans to ensure accuracy, particularly in safety-critical applications like self-driving cars.
ayw | 6 years ago | on: Scale (YC S16) Raises $100M from Accel and Founders Fund at $1B Valuation
Hey everyone! I'm Alex, CEO/founder of Scale!
I just wanted to chime in that we're a YC company as well (S16), and I'm thankful to the HN community for having been supportive through our whole journey.
ayw | 6 years ago | on: Lyft releases self-driving research dataset
Hi, I'm the CEO of Scale.ai.
This comment does not represent the company's viewpoint, and cardigan is not speaking on behalf of Scale.
We are very excited to have been able to work with Lyft in open-sourcing this dataset and advancing the research community. We are also very grateful to Lyft for choosing to leverage our point cloud viewer and have credited the annotations to us on their launch page.
ayw | 7 years ago | on: Show HN: Training Data for Robot Dogs
:) we care about our labels!
ayw | 7 years ago | on: Show HN: Training Data for Robot Dogs
You never know what gets funded these days...
ayw | 7 years ago | on: How to make MongoDB not suck for analytics
You just need to read the oplog, so it only needs to track your saves.
In general, you probably should have at least something in your stack which reads all changes from your DB, at the very least for backup reasons.
ayw | 7 years ago | on: How to make MongoDB not suck for analytics
For better or for worse, MongoDB tends to be easier for developers move quickly, so it ends up getting adopted quite a bit. This is more about how to deal with it after it's already in your stack.
page 1
We’ve built this index for autonomous driving datasets (https://scale.com/open-datasets) and are building that out for other domains right now.
Open source data has been a pillar to progress in ML (starting with ImageNet). It should continue to be the case that data that enables researches is sufficiently democratized.